
1. @property 后面可以有哪些修饰符?本质?
线程安全的: atomic, nonatomic
访问权限的: readonly, readwrite
内存管理(ARC) assign,strong,weak,copy
内存管理(MRC)assign, retain,copy
指定方法名称: setter= getter=
本质:
1.线程安全(系统默认是atomic)
atomic: Objc使用的一种线程保护技术,基本上来讲,是防止在写未完成的时候被另外一个线程读取,造成数据错误。而这种机制是耗费系统资源的,所以在iPhone这种小型设备上,如果没有使用多线程间的通讯编程,那么nonatomic是一个非常好的选择。
nonatomic: 禁止多线程,变量保护,提高性能。
2.访问权限:
readonly 表示只读, 也就是修饰的属性只有getter没有setter
readwrite 可读写, 也就是修饰的属性既有setter又有getter
3和4 我就要比较着来说了
(1)Strong和 retain
相同点:
strong 和 retain 都是针对对象类型进行内存管理. 如果去修饰基本数据类型,Xcode会直接报错. 当给对象类型使用此修饰符时,setter方法会先将旧的对象属性release掉,再将新的对象赋值给属性并对该对象进行一次retain操作, 两者都会增加对象的引用计数
不同点:
strong一般用于ARC环境, retain 用于MRC环境.
(2) assign 和 weak
相同点:
assign和weak不会牵扯到内存管理,不会增加引用计数
不同点:
assign 可修饰基本数据类型 也可修饰OC对象, 但如果修饰对象类型指向的是一个强指针, 当他指向的这个指针释放后, 他仍指向这块内存,必须手动给其置为nil, 否则就会产生野指针,如果还通过此指针操作那块内存,便会导致EXC_BAD_ACCESS错误,调用了已经释放的内存空间; 而weak 只能修饰OC对象, 且相对assign比较安全, 如果指向的对象消失了,那么他会自动置为nil,不会产生野指针.
(3) copy、strong 和 可变、不可变类型
1) copy 和 strong 都可修饰不可变类型,但一般用copy
一般用copy修饰不可变的, 因为安全, 可以保证其封闭性.
因为用copy修饰,setter方法中会自动判断如果来源,如果是不可变的,那和Strong一样,进行浅拷贝,会增加其引用计数,如果是可变的那么就深拷贝,不会增加其引用计数. 所以如果如果项目中这样的不可变对象(比如NSString)多的话,当一定数量if判断消耗的时间累加起来就会影响性能.
所以,只需要记住一点,当你给你的不可变对象 赋值时, 如果来源是可变的,那么就用copy, 如果来源是不可变类型的,就用strong.
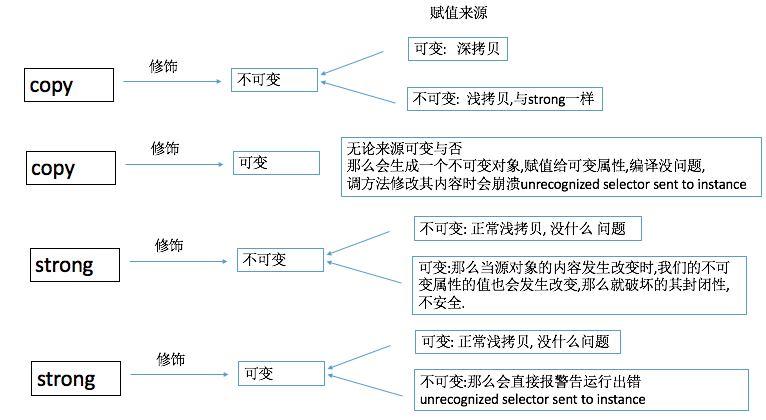
注:如果当strong修饰不可变的, 如果来源是不可变得,那么同上,没有问题. 如果来源是可变的时, 那么当源对象变化时,我们的不可变属性也会跟着变化,那么就破坏了其封闭性, 就不安全了.
2) 如果用 copy 修饰 可变类型 会出现什么问题?
Copy 修饰 可变的对象的话, 会生成一个不可变的NSCFConstantSting对象,赋值给可变属性,编译没问题, 调方法修改其内容时崩溃. unrecognized selector sent to instance
1 | 总结 |
3.block使用时的一些情况以及防止循环引用
block 在实现时就会对它引用到的它所在方法中定义的栈变量进行一次只读拷贝,然后在 block 块内使用该只读拷贝
- 并不是所有的Block中使用self,都会导致循环引用!
在AFN的 block { xxx self.view } 使用self,并不会导致循环引用!
在AFN中为什么不会出现循环引用,原因很简单,不用看底层,因为self不持有AFN的block,只是AFN的block持有self,仅仅是单向持有,并没有相互强引用~所以不会造成循环引用,就像你在oneVC中使用twoVC里面定义blcok不会出现循环引用一样,UIView动画也一个道理~
- 使用系统自带的UIView 的Blcok,控制器能被销毁–>说明没有发送循环引用。

原理: UIView的调用的是类方法,当前控制器不可能强引用一个类 ,所以循环无法形成 –> 动画block不会造成循环引用的原因。
- 那什么情况下会导致循环引用呢? –> 自定义Block
1 | 小总结: |
- block使用什么修饰,为什么?
block本身是像对象一样可以retain,和release。但是,block在创建的时候,它的内存是分配在栈(stack)上,而不是在堆(heap)上。他本身的作于域是属于创建时候的作用域,一旦在创建时候的作用域外面调用block将导致程序崩溃。
使用retain也可以,但是block的retain行为默认是用copy的行为实现的,
因为block变量默认是声明为栈变量的,为了能够在block的声明域外使用,所以要把block拷贝(copy)到堆,所以说为了block属性声明和实际的操作一致,最好声明为copy。
4.通知,代理,KVO的区别,以及通知的多线程问题
1. delegate
delegation的基本特征是:一个controller定义了一个协议(即一系列的方法定义)。该协议描述了一个delegate对象为了能够响应一个controller的事件而必须做的事情。协议就是delegator说,“如果你想作为我的delegate,那么你就必须实现这些方法”。
实现这些方法就是允许controller在它的delegate能够调用这些方法,而它的delegate知道什么时候调用哪种方法。delegate可以是任何一种对象类型,因此controller不会与某种对象进行耦合,但是当该对象尝试告诉委托事情时,该对象能确定delegate将响应。
#####delegate的优势:
- 非常严格的语法。所有将听到的事件必须是在delegate协议中有清晰的定义。
- 如果delegate中的一个方法没有实现那么就会出现编译警告/错误
- 协议必须在controller的作用域范围内定义
- 在一个应用中的控制流程是可跟踪的并且是可识别的;
- 在一个控制器中可以定义定义多个不同的协议,每个协议有不同的delegates
- 没有第三方对象要求保持/监视通信过程。
能够接收调用的协议方法的返回值。这意味着delegate能够提供反馈信息给controller
#####缺点:需要定义很多代码:1.协议定义;2.controller的delegate属性;3.在delegate本身中实现delegate方法定义
- 在释放代理对象时,需要小心的将delegate改为nil。一旦设定失败,那么调用释放对象的方法将会出现内存crash
- 在一个controller中有多个delegate对象,并且delegate是遵守同一个协议,但还是很难告诉多个对象同一个事件,不过有可能。
notification
在iOS应用开发中有一个”Notification Center“的概念。它是一个单例对象,允许当事件发生时通知一些对象。它允许我们在低程度耦合的情况下,满足控制器与一个任意的对象进行通信的目的。这种模式的基本特征是为了让其他的对象能够接收到在该controller中发生某种事件而产生的消息,controller用一个key(通知名称)。这样对于controller来说是匿名的,其他的使用同样的key来注册了该通知的对象(即观察者)能够对通知的事件作出反应。
#####通知优势:
1.不需要编写多少代码,实现比较简单;
2.对于一个发出的通知,多个对象能够做出反应,即1对多的方式实现简单
3.controller能够传递context对象(dictionary),context对象携带了关于发送通知的自定义的信息
#####缺点:
- 在编译期不会检查通知是否能够被观察者正确的处理;
- 在释放注册的对象时,需要在通知中心取消注册;
- 在调试的时候应用的工作以及控制过程难跟踪;
- 需要第三方对喜爱那个来管理controller与观察者对象之间的联系;
- controller和观察者需要提前知道通知名称、UserInfo dictionary keys。如果这些没有在工作区间定义,那么会出现不同步的情况;
- 通知发出后,controller不能从观察者获得任何的反馈信息
KVO
KVO是一个对象能够观察另外一个对象的属性的值,并且能够发现值的变化。前面两种模式更加适合一个controller与任何其他的对象进行通信,而KVO更加适合任何类型的对象侦听另外一个任意对象的改变(这里也可以是controller,但一般不是controller)。这是一个对象与另外一个对象保持同步的一种方法,即当另外一种对象的状态发生改变时,观察对象马上作出反应。它只能用来对属性作出反应,而不会用来对方法或者动作作出反应。
优点:
- 能够提供一种简单的方法实现两个对象间的同步。例如:model和view之间同步;
- 能够对非我们创建的对象,即内部对象的状态改变作出响应,而且不需要改变内部对象(SKD对象)的实现;
- 能够提供观察的属性的最新值以及先前值;
- 用key paths来观察属性,因此也可以观察嵌套对象;
完成了对观察对象的抽象,因为不需要额外的代码来允许观察值能够被观察
#####缺点:我们观察的属性必须使用strings来定义。因此在编译器不会出现警告以及检查;
- 对属性重构将导致我们的观察代码不再可用;
- 复杂的“IF”语句要求对象正在观察多个值。这是因为所有的观察代码通过一个方法来指向;
- 当释放观察者时不需要移除观察者。
总结:
从上面的分析中可以看出3中设计模式都有各自的优点和缺点。其实任何一种事物都是这样,问题是如何在正确的时间正确的环境下选择正确的事物。下面就讲讲如何发挥他们各自的优势,在哪种情况下使用哪种模式。注意使用任何一种模式都没有对和错,只有更适合或者不适合。每一种模式都给对象提供一种方法来通知一个事件给其他对象,而且前者不需要知道侦听者。在这三种模式中,我认为KVO有最清晰的使用案例,而且针对某个需求有清晰的实用性。而另外两种模式有比较相似的用处,并且经常用来给controller间进行通信。那么我们在什么情况使用其中之一呢?
根据我开发iOS应用的经历,我发现有些过分的使用通知模式。我个人不是很喜欢使用通知中心。我发现用通知中心很难把握应用的执行流程。UserInfo dictionaries的keys到处传递导致失去了同步,而且在公共空间需要定义太多的常量。对于一个工作于现有的项目的开发者来说,如果过分的使用通知中心,那么很难理解应用的流程。
我觉得使用命名规则好的协议和协议方法定义对于清晰的理解controllers间的通信是很容易的。努力的定义这些协议方法将增强代码的可读性,以及更好的跟踪你的app。代理协议发生改变以及实现都可通过编译器检查出来,如果没有将会在开发的过程中至少会出现crash,而不仅仅是让一些事情异常工作。甚至在同一事件通知多控制器的场景中,只要你的应用在controller层次有着良好的结构,消息将在该层次上传递。该层次能够向后传递直至让所有需要知道事件的controllers都知道。
当然会有delegation模式不适合的例外情况出现,而且notification可能更加有效。例如:应用中所有的controller需要知道一个事件。然而这些类型的场景很少出现。另外一个例子是当你建立了一个架构而且需要通知该事件给正在运行中应用。
根据经验,如果是属性层的时间,不管是在不需要编程的对象还是在紧紧绑定一个view对象的model对象,我只使用观察。对于其他的事件,我都会使用delegate模式。如果因为某种原因我不能使用delegate,首先我将估计我的app架构是否出现了严重的错误。如果没有错误,然后才使用notification。
5.KVO 的实现原理
KVO(key-value observe)是在KVC的基础上实现的一种用于监听属性变化的设计模式;如果对某个类的某个属性设置了KVO,那么当这个属性发生变化时,就会触发监听方法,从而知道属性变化了。如果本类一个属性的改变会影响到其他多个属性的变化,我们也会经常自己重写这个属性的set方法,用来监听他的变化,
<<<但是如果不是本类的属性,我们就没办法重写其set方法了,这个时候KVO就可以上场了,其实KVO本质上也是重写set方法,而整个过程依赖于runtime才能实现。>>>
KVO是根据iOS runtime实现的,当监听某个对象(_kvoTest)的某个属性时,KVO会创建这个对象的子类,并重写我们监听的属性(keyPath)的set方法,具体实现可能是下面这个样子。
1 |
|
didChangeValueForKey:方法执行完之后,KVO会根据注册时option返回不同的字典
上面我们提到了KVO是建立在KVC基础上的,可以看到,如果不通过KVC改变属性,那么set方法就不会执行,那么KVO也就没办法监听属性的变化了
再具体一点(原理)
我们都说他是通过runtime实现的,是因为这个操作是运行的时候动态添加的,可以多阅读一些关于runTime的文章,知道原理,用起来更顺手,也会有更多的想法。
当观察对象时,KVO机制动态创建一个新的名为:NSKVONotifying_对象名 的新类,该类继承自目标对象的本类,且 KVO 为 NSKVONotifying_对象名 重写观察属性的 set 方法。在这个过程,被观察对象的 isa 指针从指向原来的对象,被 KVO 机制修改为指向系统新创建的子类 NSKVONotifying_对象名 类,来实现当前类属性值改变的监听,这也就是前面所说的“黑魔法”;我还试了一下,创建一个新的名为“NSKVONotifying_对象名”的类,发现系统运行到注册 KVO 的代码时,iOS10及以下会崩溃,iOS11下控制台打印警告:
1 | [general] KVO failed to allocate class pair for name NSKVONotifying_KVOTestModel, |
5. GCD的简单应用
使用GCD如何实现这个需求:A、B、C 三个任务并发,完成后执行任务 D。
1 | dispatch_queue_t globalQueue = dispatch_get_global_queue(0, 0); |
6.GCD 死锁总结(具体还没整理)
GCD提供了功能强大的任务和队列控制功能,相比于NSOperationQueue更加底层,因此如果不注意也会导致死锁。
所谓死锁,通常指有两个线程A和B都卡住了,并等待对方完成某些操作。A不能完成是因为它在等待B完成。但B也不能完成,因为它在等待A完成。于是大家都完不成,就导致了死锁(DeadLock)。
7.常用加密方式
base64
md5
AES
RSA
归档和解档(本地持久化)
归档是指用某种格式来保存一个或多个对象,以便以后还原这些对象的过程。归档是将数据持久化的一种方式(所谓数据持久化,就是指在IOS开发过程中,将数据保存到本地,能够让程序的运行更加流畅)。
想要归档的数据对象,需要遵守NSCoding协议,并且该对象对应的类必须提供encodeWithCoder:和initWithCoder:方法。
归档就是将临时数据保存成本地文件。
归档的缺点:归档的形式来保存数据,只能一次性归档保存以及一次性解压。所以只能针对小量数据,而且对数据操作比较笨拙,即如果想改动数据的某一小部分,还是需要解压整个数据或者归档整个数据。
8.iOS视图控制对象生命周期
视图控制对象通过alloc和init来创建,但是视图控制对象不会在创建的那一刻就马上创建相应的视图,而是等到需要使用的时候才通过调用loadView来创建,这样的做法能提高内存的使用率。
- init-初始化程序
- viewDidLoad-加载视图
- viewWillAppear-UIViewController对象的视图即将加入窗口时调用;
- viewDidApper-UIViewController对象的视图已经加入到窗口时调用;
- viewWillDisappear-UIViewController对象的视图即将消失、被覆盖或是隐藏时调用;
- viewDidDisappear-UIViewController对象的视图已经消失、被覆盖或是隐藏时调用;
- viewVillUnload-当内存过低时,需要释放一些不需要使用的视图时,即将释放时调用;
- viewDidUnload-当内存过低,释放一些不需要的视图时调用。
当一个视图控制器被创建,并在屏幕上显示的时候。 代码的执行顺序
- alloc 创建对象,分配空间
- init (initWithNibName) 初始化对象,初始化数据
- loadView 从nib载入视图 ,通常这一步不需要去干涉。除非你没有使用xib文件创建视图
- viewDidLoad 载入完成,可以进行自定义数据以及动态创建其他控件
- viewWillAppear视图将出现在屏幕之前,马上这个视图就会被展现在屏幕上了
- viewDidAppear 视图已在屏幕上渲染完成
#####当一个视图被移除屏幕并且销毁的时候的执行顺序,这个顺序差不多和上面的相反
- viewWillDisappear视图将被从屏幕上移除之前执行
- viewDidDisappear视图已经被从屏幕上移除,用户看不到这个视图了
- dealloc视图被销毁,此处需要对你在init和viewDidLoad中创建的对象进行释放
总结
关于viewDidUnload在发生内存警告的时候如果本视图不是当前屏幕上正在显示的视图的话,viewDidUnload将会被执行,本视图的所有子视图将被销毁,以释放内存,此时开发者需要手动对viewLoad、viewDidLoad中创建的对象释放内存。 因为当这个视图再次显示在屏幕上的时候,viewLoad、viewDidLoad 再次被调用,以便再次构造视图。在设备上按了Home键之后,系统也不一定会调用这个方法,因为IOS4之后,系统允许将APP在后台挂起,并将其继续滞留在内存中,因此,viewcontroller并不会调用这个方法来清除内存。
